Jin Daily AI Trivia: DeepSeek-OCR and DeepEncoder Shock the AI World — Again!!
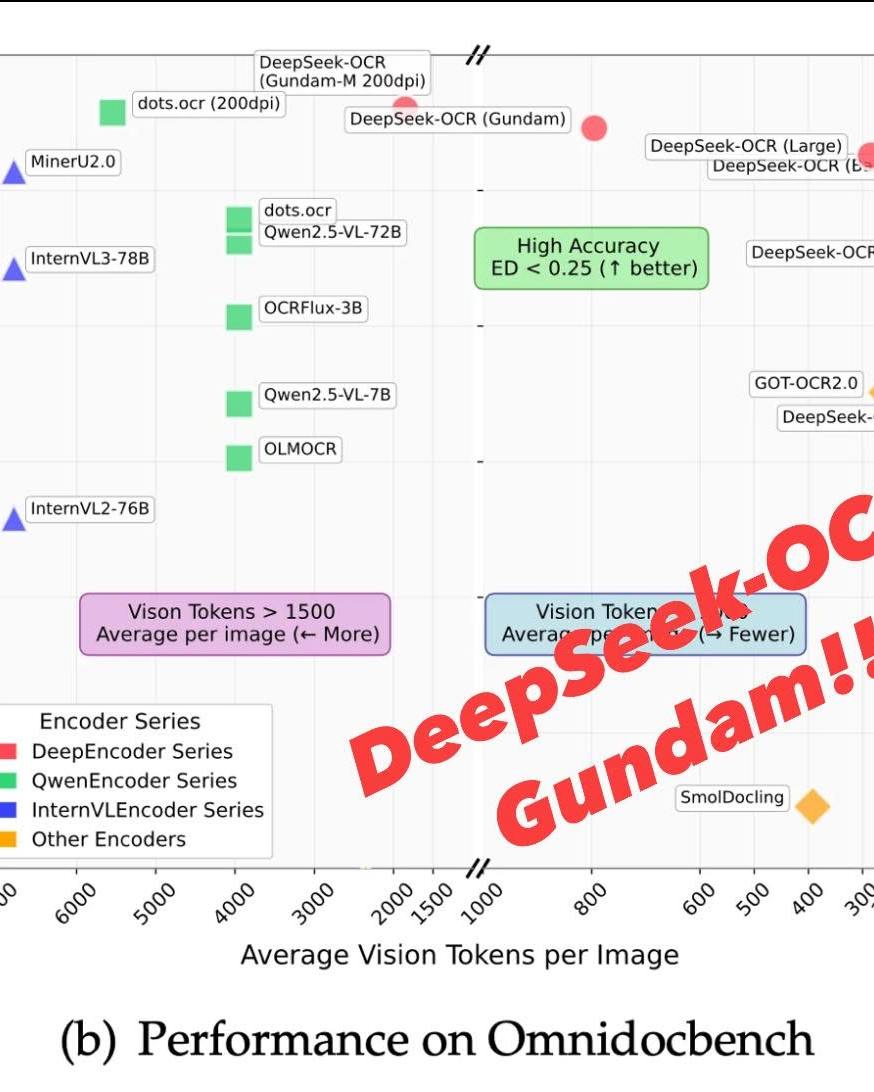
Building on the earlier DeepSeek-VL design, the DeepSeek team has done it again — they’ve found a way to compress complex data into images, achieving 10–20× compression with minimal loss.
This breakthrough could completely reshape how AI models handle information — just like when DeepSeek first redefined open source reasoning models and MoE efficiency.
Key Highlights: • Context Optical Compression: Converts text context into visual tokens, reaching up to 10–20× compression while maintaining accuracy. • DeepEncoder Architecture: Combines local pixel structure capture and global semantic alignment through a 16× convolutional compression module for extreme efficiency. • “Gundam Mode”: A dynamic resolution setup fine-tuned for dense, high-resolution document parsing, delivering <800 tokens per page and about 87% OCR accuracy even on complex layouts.
Yes, that Gundam!!!
Tech Otaku Save The World!!