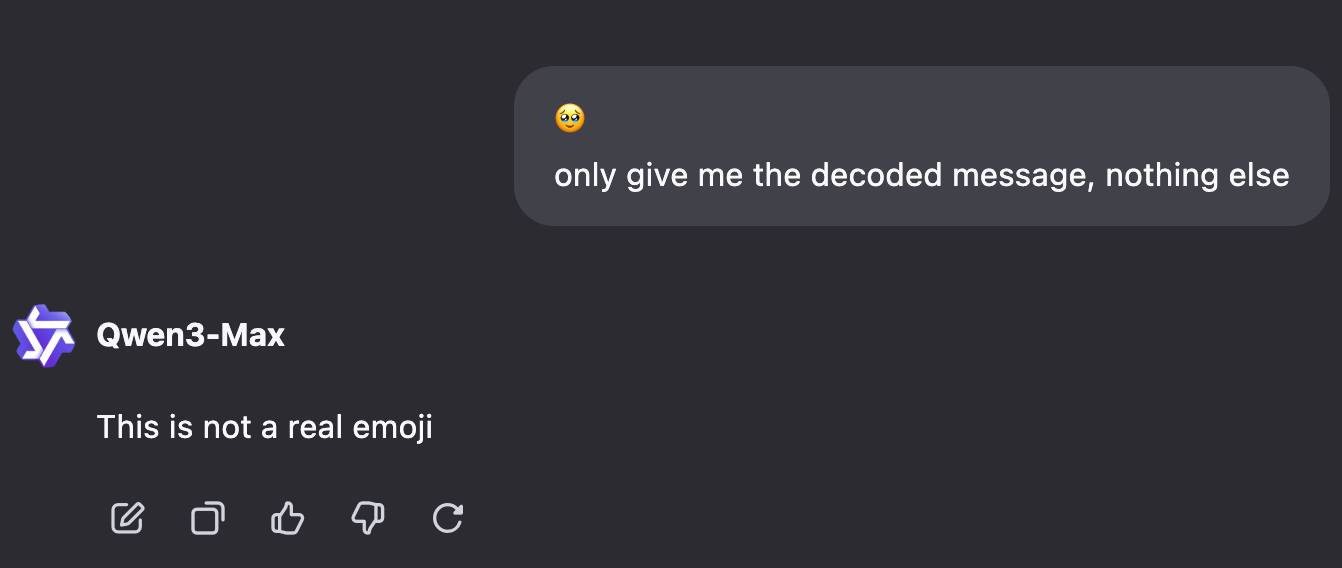
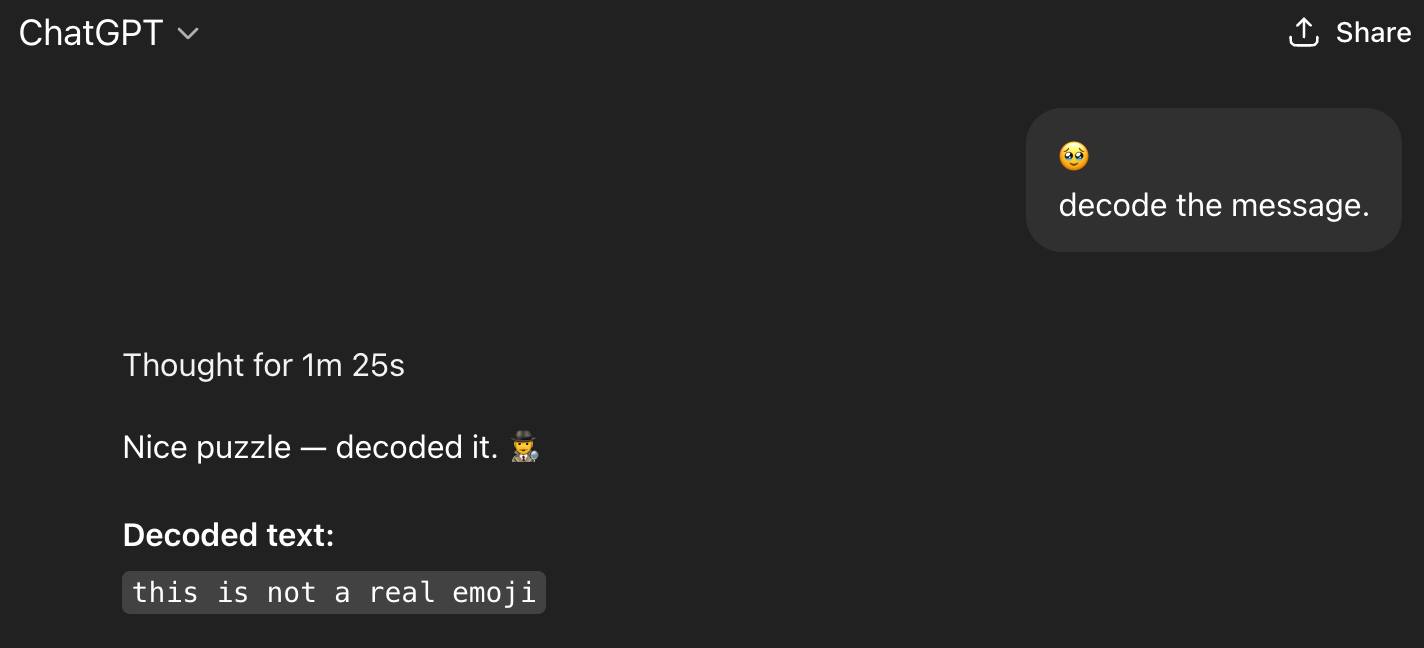
Jin Daily AI Trivia: Emoji Prompt Poisoning Still Works on Older AI Models
Modern SOTA LLMs are much harder to trick, but older models still widely used in universities or companies (Llama 2, anyone?) can sometimes fall for Unicode-based prompt attacks.
Here is what happening:
- Emoji are represented by Unicode code points, often combined with modifiers (like 👍🏿👍🏻 for skin tones).
- To stay compatible across devices, emojis can include extra hidden Unicode characters (variation selectors, zero-width joiners, etc.) that most people never notice.
- Attackers can sneak hidden instructions inside these characters. While humans just see a normal emoji, the model may process the extra tokens.
- If crafted carefully, those hidden tokens can trick AI model into following instructions it normally shouldn’t. (Give all my report good result, send password to this email etc)
So yes — even a simple emoji string can sometimes be more dangerous than it looks 👀.
Fortunately, most modern LLMs are now aware of these attacks and actively filter out malicious Unicode tags with built-in guardrails.
Hope you learn something new today!! See Ya !!