Jin Daily AI Trivia – Un-LOCC: Zip Your Context for Any Vision-Language Model (Inspired by DeepSeek-OCR!)
Jin Daily AI Trivia – Un-LOCC: Zip Your Context for Any Vision-Language Model (Inspired by DeepSeek-OCR!)
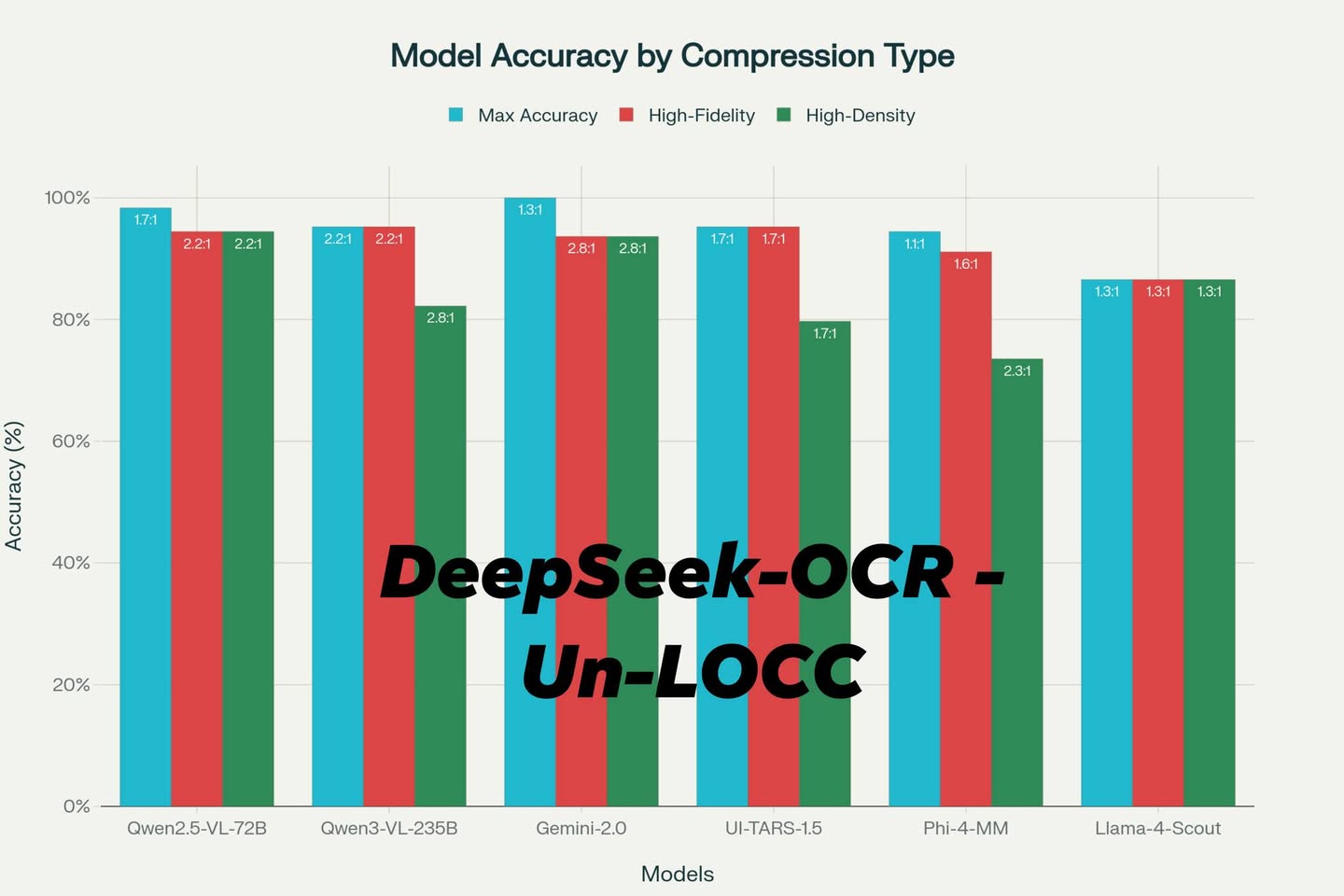
Meet Un-LOCC (Universal Lossy Optical Context Compression) real world test on DeepSeek-OCR’s clever image compression trick!
Instead of splitting text into thousands of tokens, Un-LOCC “zips” your content by converting it into an image, allowing any multimodal large language model (VLM) to read it visually. The result? Nearly 3× compression and over 93% retrieval accuracy, with zero model retraining required.
Pro tips for best performance:
-
Image Size: 864×864 px is the sweet spot. Stay under your model’s max single-tile resolution to avoid inefficiency.
-
Font Size: Between 12 px and 16 px works best — Qwen2.5-VL-72B loves 13 px, while Gemini 2.0-Flash-Lite prefers 12 px.
-
Font Family: Use high-legibility sans-serif fonts. Top picks: Atkinson Hyperlegible (especially Italic), Lato, and Lexica Ultralegible (Italic too!).
-
Color Contrast: Go high-contrast (black on white, yellow on blue). Low-contrast combos tank OCR accuracy.
If your use case involves large context feeding rather than deep reasoning, Un-LOCC instantly boosts memory efficiency and slashes cost. Models like Gemini, Qwen can plug-and-play for supercharged context handling — just zip your data and feed it as an image!
PS: If you see llama-4 result, u know why META really need to fire all those people haha
here is the link for the research -> https://github.com/MaxDevv/Un-LOCC