Jin Daily AI Trivia – What Google didn’t tell you about the super fast new Gemini-3-Flash?
Jin Daily AI Trivia – What Google didn’t tell you about the super fast new Gemini-3-Flash?
-
Runs up to 3x faster than Gemini-3-Pro.
-
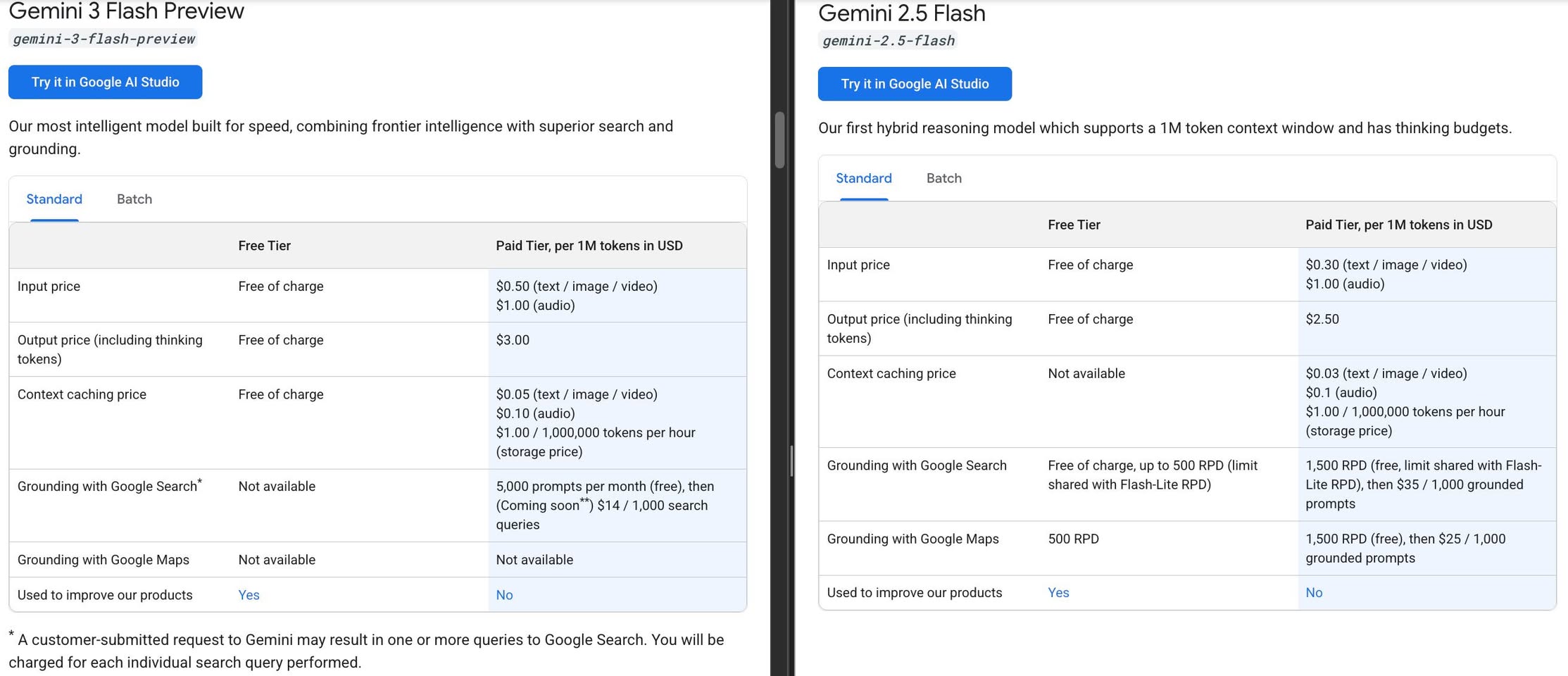
Priced at $0.50 / 1M input and $3.00 / 1M output tokens; about 25% more expensive than Gemini-2.5-Flash despite the “1/4 Pro price” marketing.
-
SWE-bench score is around 78%, slightly higher than Gemini-3-Pro in some third-party benchmarks.
-
Gemini-3-Flash finally gets a native PDF ingestion pipeline (and supports more document formats), similar to the Pro model, while Gemini-2.5-Flash relied on a PDF vision decoder.
-
Video ingestion should be cheaper overall, but high-res native PDF ingestion will cost more because of much higher visual token usage.
-
Available free in the Gemini app and Gemini CLI for general usage right now.
The catch: Gemini-3-Flash API calls won’t support Google Search grounding until January 5, 2026, although you can still use grounding in the Gemini app and CLI flows that Google controls.
If you need Google Maps grounding, Gemini-3-Flash is currently not supported, so you’ll still need to fall back to Gemini-2.5-Flash for now.
Here’s the technical bit that actually excites me:
Gemini-3 (both Pro and Flash) introduces a media_resolution parameter, which means you can push super high-resolution PDFs or images and the model will process them with much higher visual token budgets – up to around 2,240 tokens at the ultra_high tier.
Older Gemini 2.x models were effectively capped at about 258 visual tokens per image tile, which is one big reason why a simple receipt OCR app would often be wrong 20–30% of the time on messy, dense layouts.
Personally can’t wait for a Gemini-3-Flash-Lite tier: cheaper, high res ingestion, and finally usable as the main engine in a production workflow pipeline – instead of having to jump to Mistral or a specialized OCR model for every document-heavy job.
Hope you learned something new today. See you in the next Jin Daily AI Trivia!