Jin Daily AI Trivia: Too little RAM to run a full FP16 LLM? What about a 1-bit model instead?
Jin Daily AI Trivia: Too little RAM to run a full FP16 LLM? What about a 1-bit model instead?
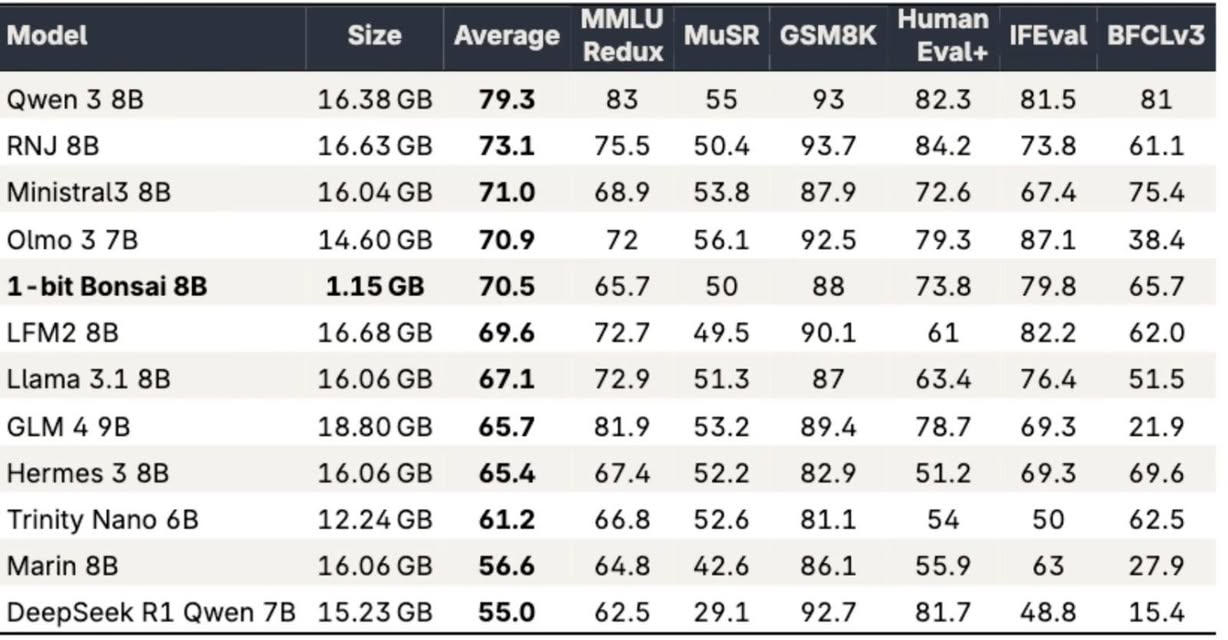
PrismML — a US AI company spun out of Caltech research — has just announced its latest model: 1-bit Bonsai 8B. The entire model weighs only around 1.28GB in MLX 1-bit format.
I ran it on my M4 Pro and got about 136 tokens/sec — which feels basically instant.
Bonsai 8B is a truly end-to-end 1-bit model: embeddings, attention, MLP, and the LM head are all 1-bit.
That makes it: ~14× smaller ~8× faster ~5× more energy efficient
compared to full-precision equivalents, especially on edge devices.
This is also slightly different from what I covered before — like Microsoft’s 1.58-bit models.
1-bit vs 1.58-bit: Bonsai uses strict binary weights {-1, 1} Microsoft-style models use ternary weights {-1, 0, 1}
I’ll try using it for text extraction next and see whether this actually holds up as a practical small AI model.