Jin Daily AI Trivia — Apple: "LLMs, just learn from your own crap"
Jin Daily AI Trivia — Apple: “LLMs, just learn from your own crap”
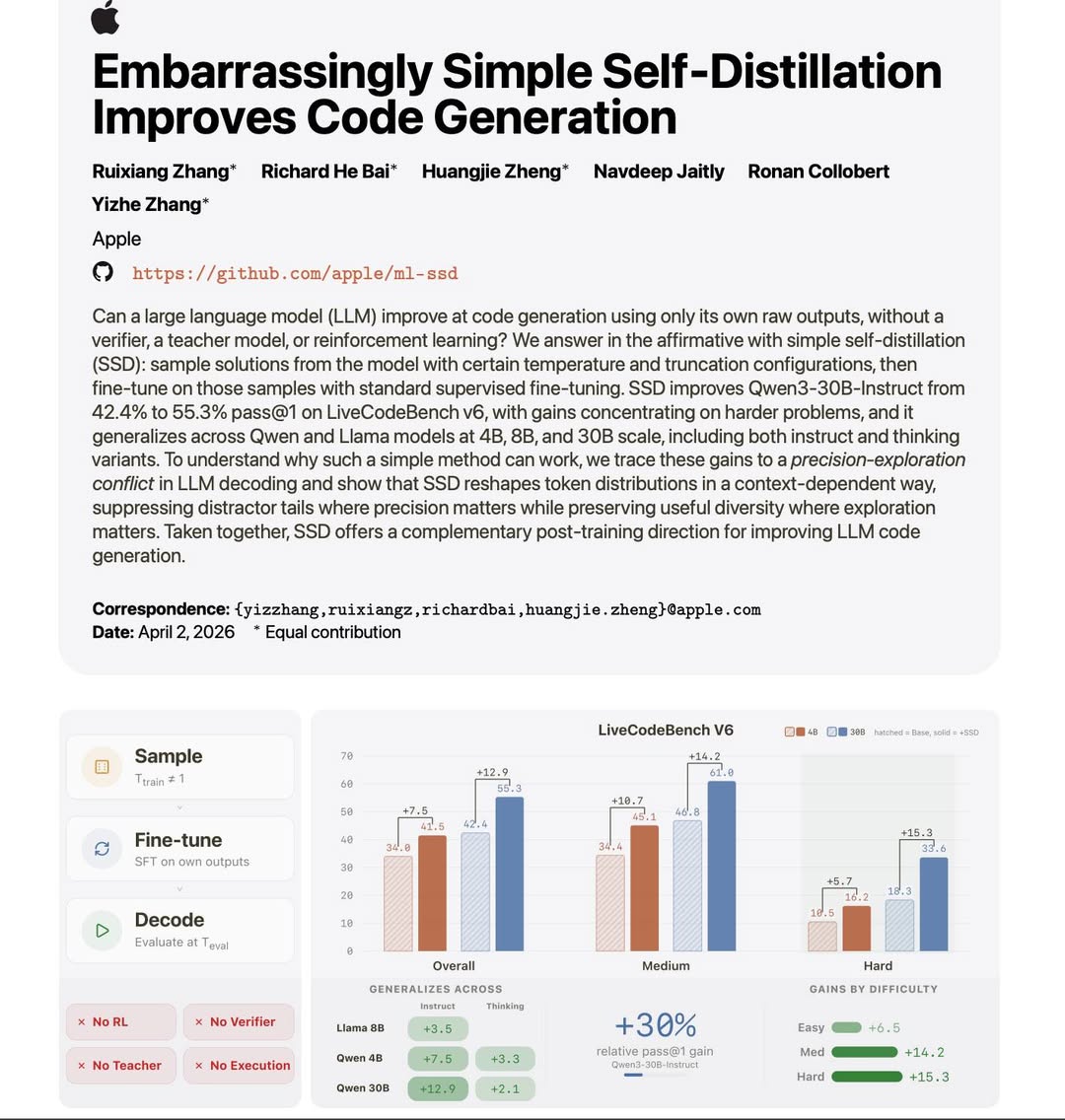
Apple researchers may have just found a surprisingly simple way to train any LLM (including dense and reasoning models) to improve themselves:
- No reinforcement learning
- No teacher model
- No verifier
- No reward model
The key idea: Lock vs Fork Lock tokens — places where accuracy must be exact (e.g., code syntax, system variables) Fork tokens — places where multiple answers are valid (e.g., different sorting methods or indexing approaches)
This simple self-distillation reshapes the probability distribution: Locks become sharper (less noise, fewer bad tokens) Forks remain flexible (multiple viable paths that temperature can explore)
If you need a simpler explanation, SSD work like this:
- Student always think out of box and can’t answer all the question.
- Let the student write one full attempt
- Reinforce the structure of how answers should look
- Over time, the student:
- Follows structure more reliably
- Still knows where to explore creatively when needed
This suggests that in code generation, correctness isn’t everything — structure and the underlying probability distribution matter more.