Daily Jin AI Trivia: What you need to know about DeepSeek V3.1
Two days ago, DeepSeek quietly dropped their new model weights on Hugging Face — just a small note on their WeChat channel, no big announcement.
So what’s new?
-
One Model to Rule Them All: DeepSeek V3 and R1 are now merged into a single big model — DeepSeek V3.1 — featuring a hybrid thinking mode switch.
-
Faster & Stronger Agents: Runs faster, with upgraded tool-calling skills.
-
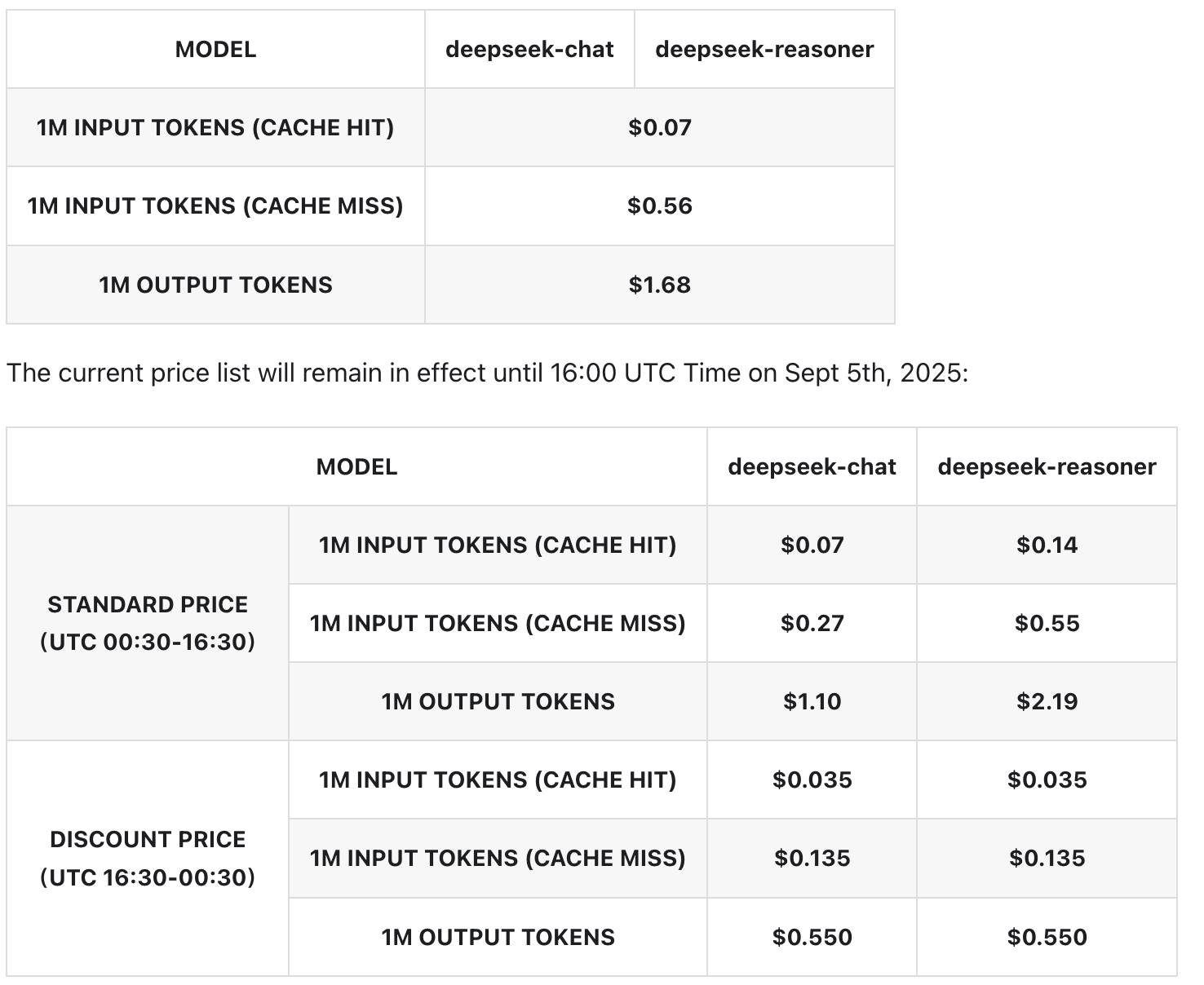
Model Specs: 671B parameters, 37B activated, 128K token window (same as before). And Only 1 pricing now.
-
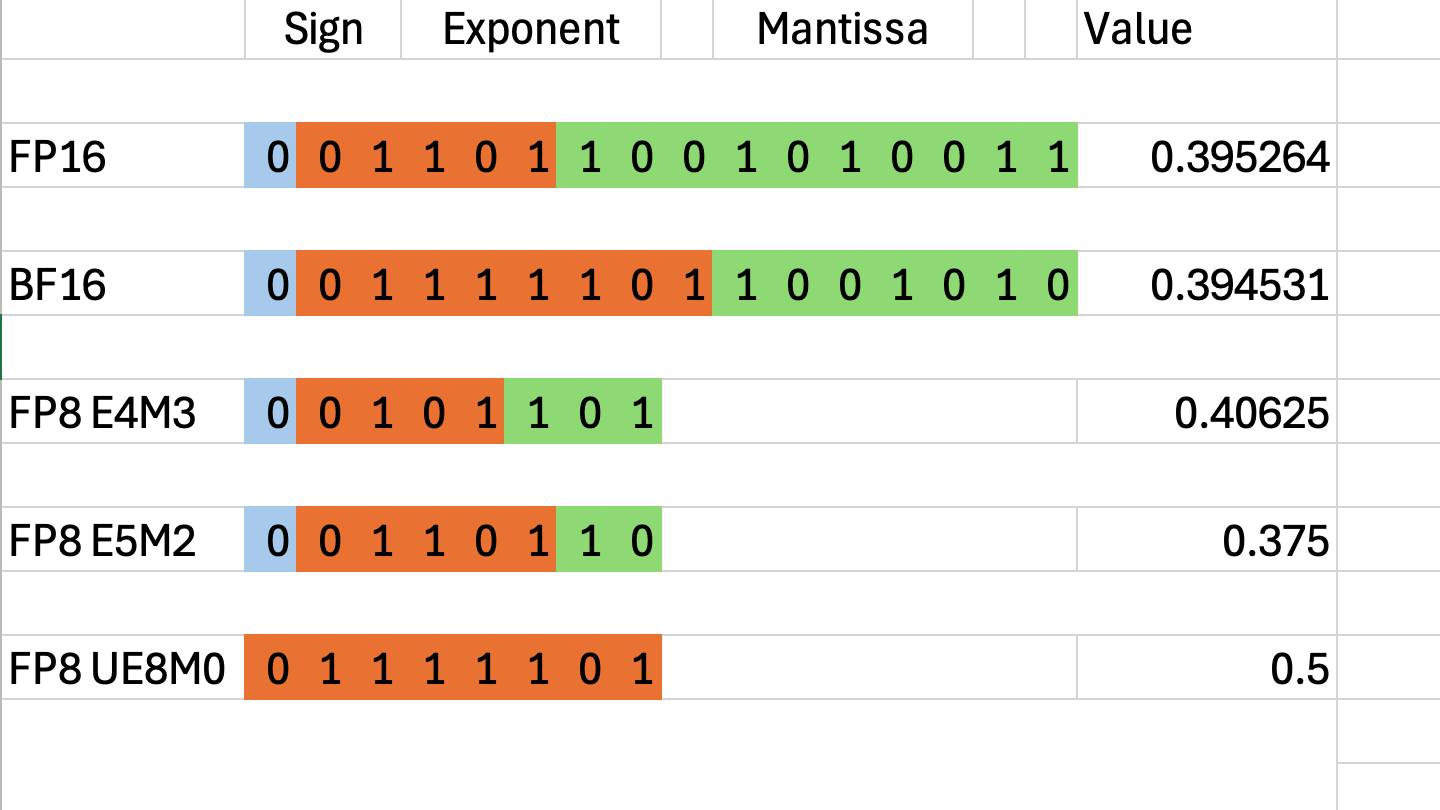
Format Upgrade: V3.1 is designed with UE8M0 FP8 (China’s NPU format) instead of MXFP8 (Nvidia’s E4M3/E5M2). In short: prioritizing width over precision — it can fit BF16 values but sacrifices some accuracy.
Jin’s Verdict:
- Much faster, uses fewer tokens per task.
- Smarter in coding, tool use, and math.
- Slightly dumber in general knowledge.
A solid upgrade worthy of the “3.1” — Unlike GPT-5 ( >_>)
Feels like a foundation model optimized for China’s own AI chips rather than Nvidia GPUs.
Quick Not Professional Review:
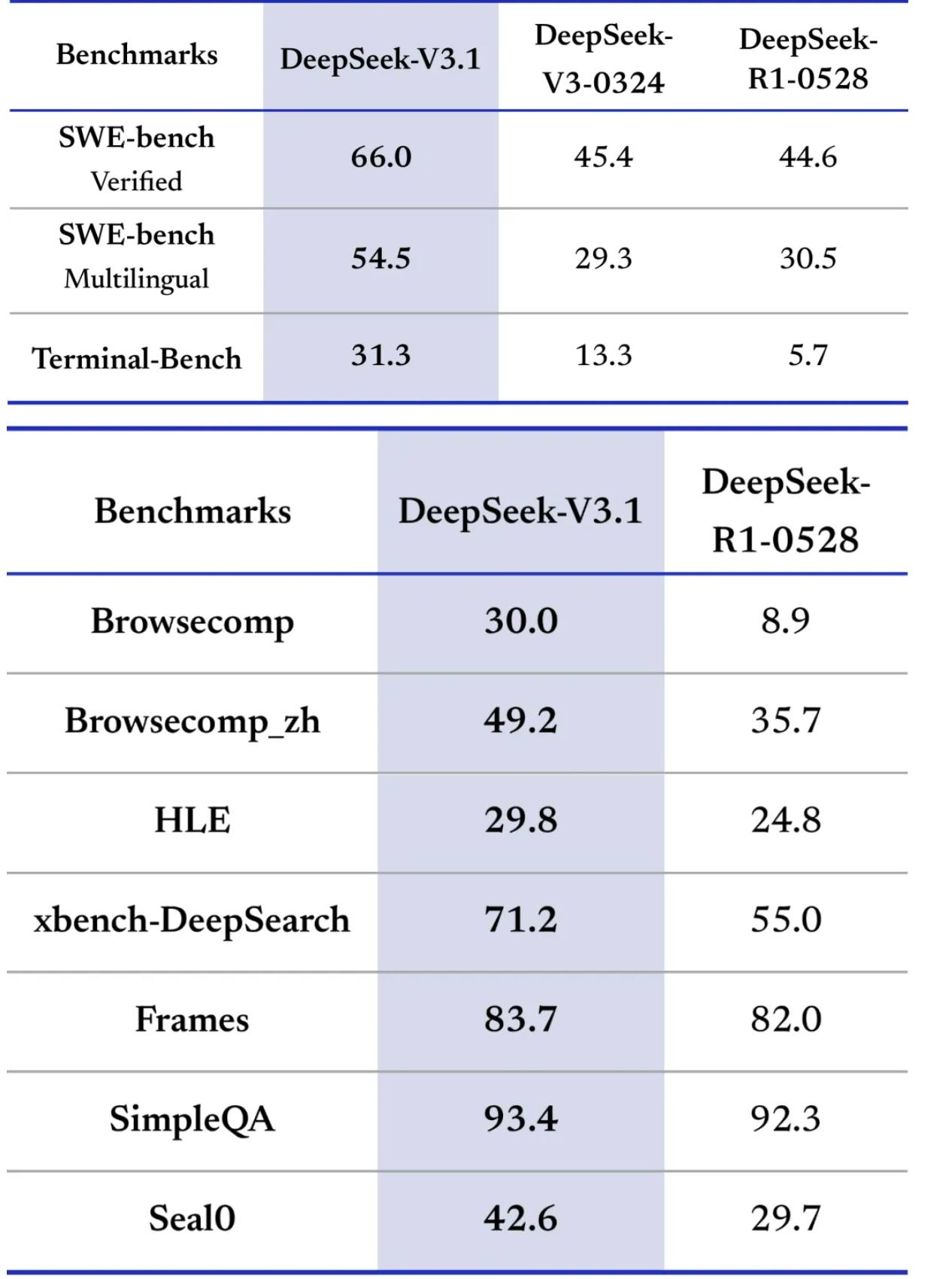
Outstanding in coding — currently #1 on the Aider Polyglot benchmark for open-source models. Honestly, I’d take it over Claude Sonnet 4.
DeepSeek’s API now supports both OpenAI and Anthropic formats, meaning you can plug it directly into Claude code https://api-docs.deepseek.com/guides/anthropic_api
The “midnight eco” cheap rate is gone, but since V3.1 outputs fewer tokens, you should still see lower costs compared to R1.
That’s it — hope you learned something new today! See ya !!